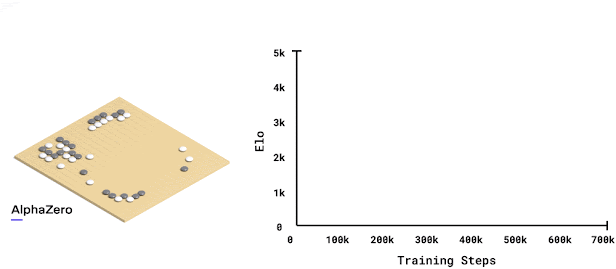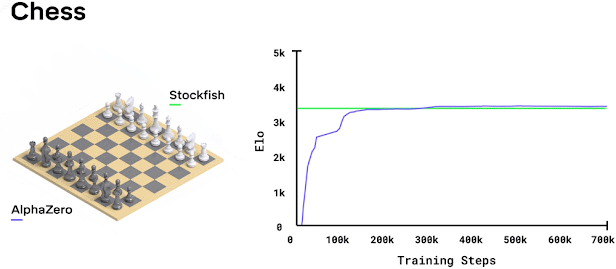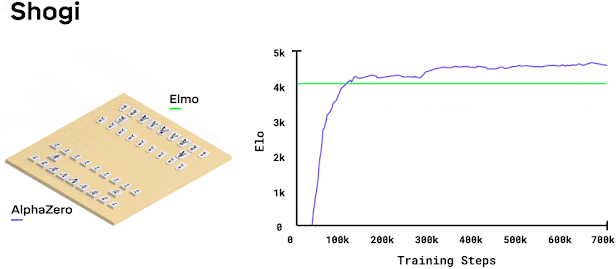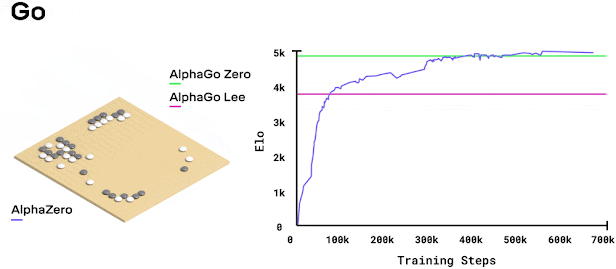
While working at Cogito NTNU, I decided to implement AlphaZero from scratch. I thought it would be straightforward. Just follow the paper, right? Wrong. It turned into months of debugging and optimization. Research papers make everything look easy because they skip all the annoying implementation details.
How AlphaZero Works
AlphaZero combines Monte Carlo Tree Search with a neural network that predicts two things: which moves are good, and who’s winning. The training loop is simple:
- Self play to generate training data
- Train the neural network on that data
- Test if the new network is better than the old one
The neural network outputs a policy vector π (move probabilities) and a value estimate \(v\in [-1,1]\) for how good the position is.
Here’s the network we used:
1 | import torch |
 Figure 1: A visualization of our
MCTS implementation showing a Tic Tac Toe board with red and white
circles (and one empty black position) on the left, and its
corresponding search tree on the right displaying visit counts and move
numbers at each node, starting from 500 visits at the root.
Figure 1: A visualization of our
MCTS implementation showing a Tic Tac Toe board with red and white
circles (and one empty black position) on the left, and its
corresponding search tree on the right displaying visit counts and move
numbers at each node, starting from 500 visits at the root.
The Loss Function
The network learns by minimizing this loss:
\[L = (z - v)^2 - \pi^T \log p + c\|\theta\|^2\]
where \(z\) is the actual game outcome, \(v\) is what the network predicted, \(\pi\) is what MCTS thinks the best moves are, \(p\) is what the network thinks, and that last term just prevents overfitting.
Making It Fast
The algorithm is only half the battle. Getting good performance required a bunch of engineering tricks that papers never mention.
Parallel Everything
Running MCTS simulations in parallel was huge for performance:
1 | import torch.multiprocessing as mp |
Smart Caching
We also added caching to avoid evaluating the same positions over and over:
1 | import numpy as np |
Results
After all the optimizations, we got some solid improvements:
- Self play was 3.2x faster
- Network training was 2.8x faster
- Memory usage dropped by 45%
We also tried path consistency optimization, which forces the value predictions to be consistent along search paths:
\[L_{PC} = \|f_v - \bar{f}_v\|^2\]
It helped the network learn faster, though honestly I’m still not 100% sure why it works so well.
The part that took forever
Implementing research papers is way harder than it looks. The papers make everything sound clean and simple, but getting something that actually runs fast requires tons of boring engineering work that never gets mentioned.
The biggest time sink was debugging why our implementation was so much slower than reported results. A lot of the speedup comes from implementation details that papers just assume you know, or don’t bother explaining because it’s “obvious” to the authors.
The code is on GitHub if you want to check it out. Fair warning: getting it to run well takes patience.